
王林楠 (Linnan Wang)
Office 351, CIT
Department of Computer Science
Brown University
Providence, RI 02906
|
|
王林楠 (Linnan Wang)
Office 351, CIT |
|
Artificial Intelligence (AI) is going to be the extension of our brains, in the same way as cars are the extension of our legs. It has already been an indispensable part of our life. Every day, AI navigates us to places, answers our queries, and recommends restaurants and movies. Overall, it amplifies what we do, augmenting our memory, giving you instant knowledge, allowing us to concentrate on doing things that are properly human.
However, designing new AI models is still reserved for experts; and the goal of my research is to democratize AI, making it accessible to everybody, such that any person regardless of their prior experiences, and any company regardless of size can deploy sophisticated AI solutions with only a few simple clicks.
I'm a senior deep learning engineer at NVIDIA. I got my Ph.D. from the CS department of Brown University, advised by Prof.Rodrigo Fonseca. Before Brown, I was a OMSCS student at Gatech while being a full time software developer at Dow Jones. I acquired my bachelor degree from University of Electronic Science and Technology of China (UESTC) at the beautiful Qing Shui He campus in 2011. I have been incredibly fortunate to work closely with Yiyang Zhao, Junyu Zhang, Yuandong Tian, Saining Xie, Yi Yang, Wei Wu, George Bosilca, and 2022 Turing Fellow Jack Dongarra.
 |
|
||
 |
|
||
 |
|
||
 |
|
 |
|
||
 |
|
||
 |
|
||
 |
|
||
 |
|
||
 |
|
||
 |
|
||
 |
|
||
 |
|
||
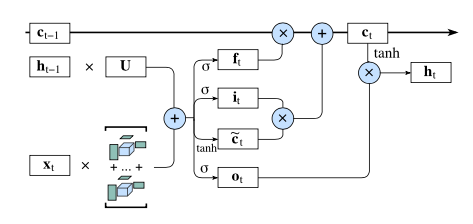 |
|
||
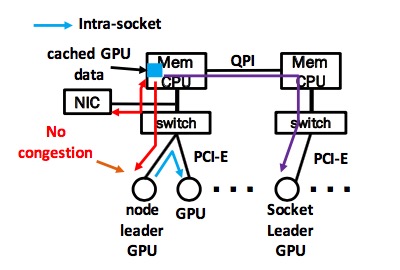 |
|
||
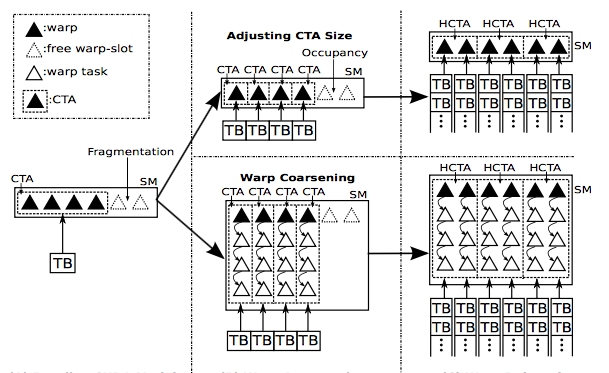 |
|
||
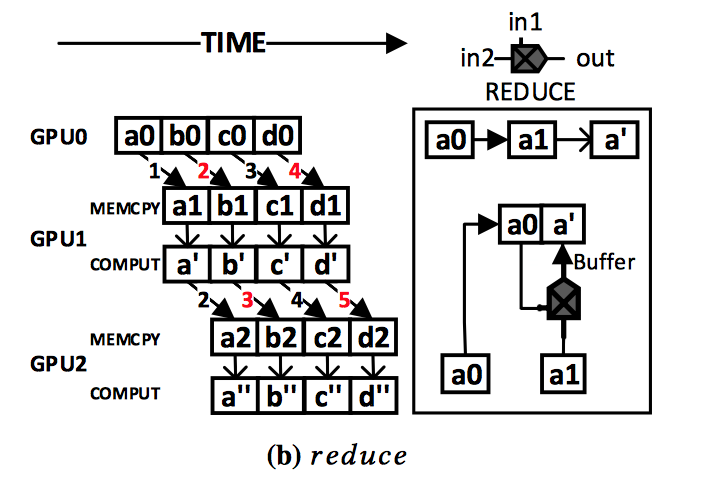 |
|
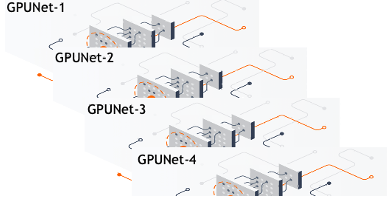
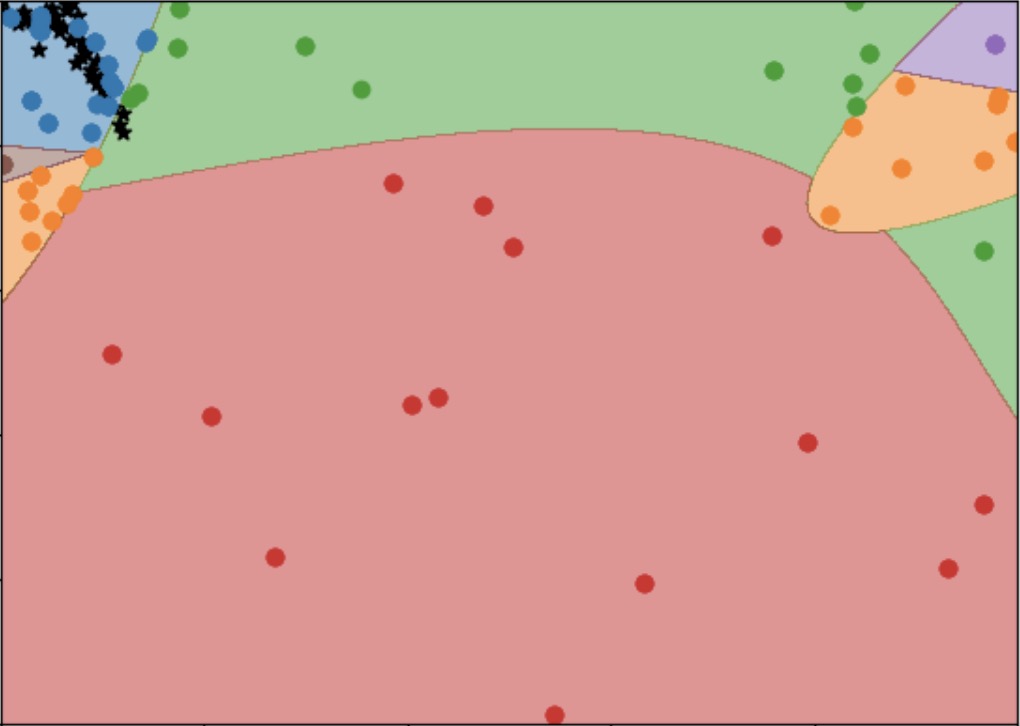
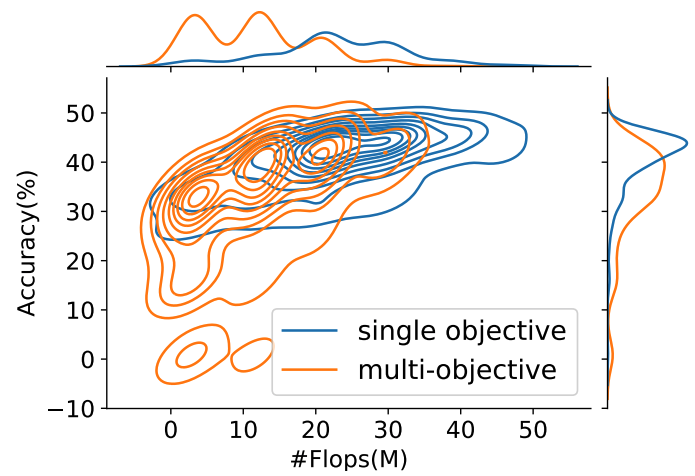
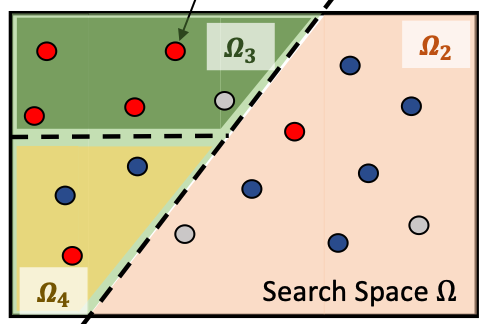
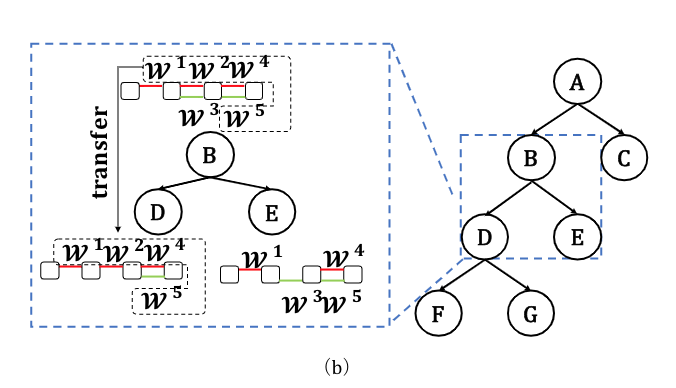
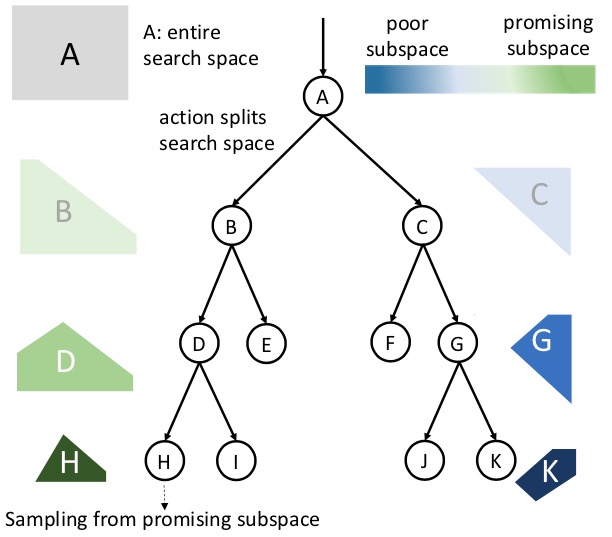
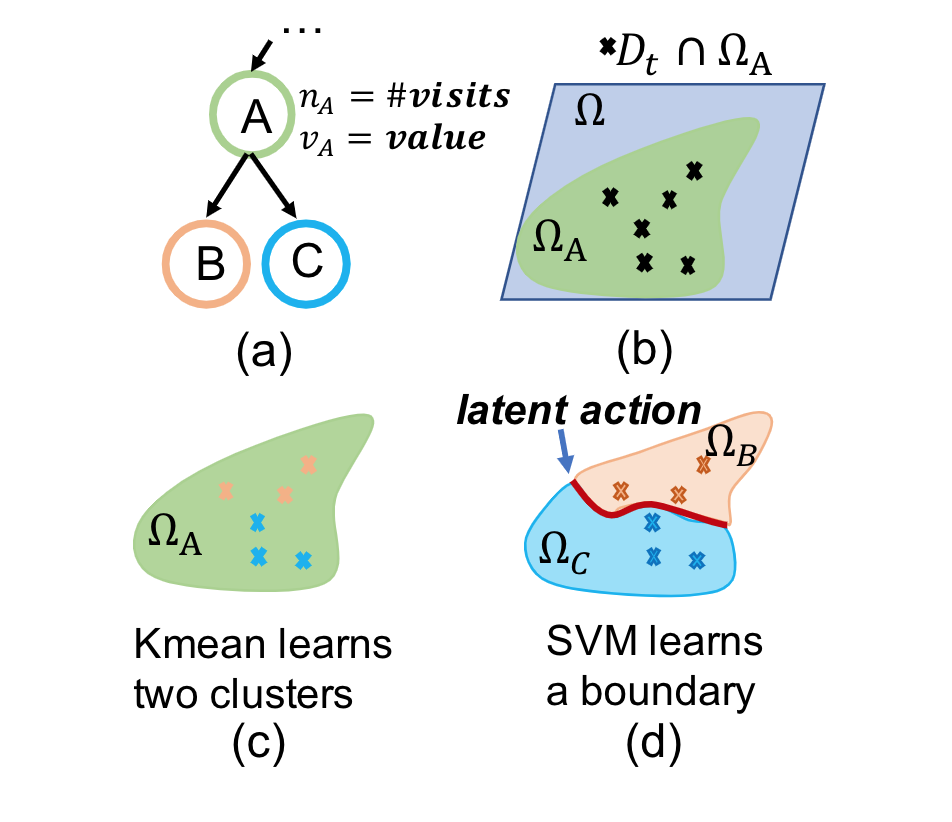
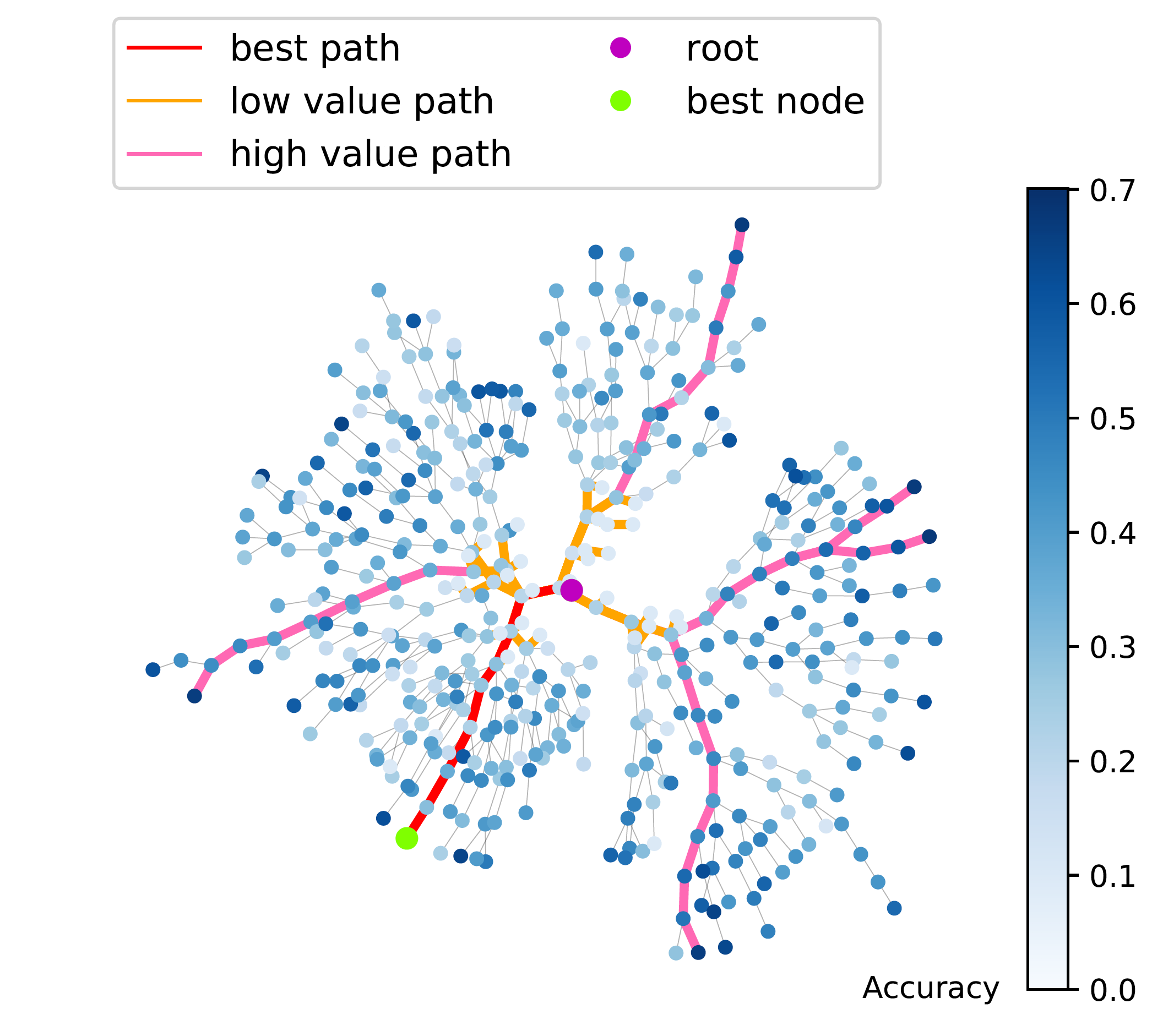
Automated Machine Learning: building an AI that builds AI.
|
||
Machine Learning System: building efficient distributed systems for AI.
|